Data and Tools
Research Topics
Client-side Information Retrieval (2025 - )
In this research project, we develop technologies that employ client-side AI running on researchers’ PCs to continuously monitor research activities and information-seeking behaviors, autonomously retrieving and providing information necessary for advancing research. This approach reduces privacy and security risks while enabling the timely delivery of information that researchers intend to search for, information they did not explicitly intend to search for but is still useful, and information that contributes to the progress of their research.
Data Search (2018 - )
This research aims to develop a data search engine for organizing the world’s open data and making it universally accessible and useful. The data search engine provides flexible and efficient access to open data by realizing queries on implications from data and data summarization through an index built by data analysis. We encourage open science and data-driven scientific decision making of the general public by establishing the data search engine.
Information Need Elicitation (2013 - )
We studied how to elicit information needs from users. Sensors, brain signals, and search behaviors such as clicks were used to estimate desired information actively and effectively.
- Makoto P. Kato, Katsumi Tanaka: To Suggest, or Not to Suggest for Queries with Diverse Intents: Optimizing Search Result Presentation. In Proc. of the 9th ACM International Conference on Web Search and Data Mining (WSDM 2016), pp. 133-142, 2016.
- Makoto P. Kato, Takehiro Yamamoto, Hiroaki Ohshima, Katsumi Tanaka: Investigating Users’ Query Formulations for Cognitive Search Intents. In Proc. of the 37th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2014), pp. 577-586, 2014.
- Shuya Ochiai, Makoto P. Kato, Katsumi Tanaka: Re-call and Re-cognition in Episode Re-retrieval: A User Study on News Re-finding a Fortnight Later. In Proc. of the 23th ACM International Conference on Information and Knowledge Management (CIKM2014), pp. 579-588, 2014.
- Makoto P. Kato, Tetsuya Sakai, Katsumi Tanaka: When Do People Use Query Suggestion? A Query Suggestion Log Analysis. Information Retrieval, 16(6), pp. 1-22, 2013.
Search as If You Were in Your Hometown (2010 - 2012)
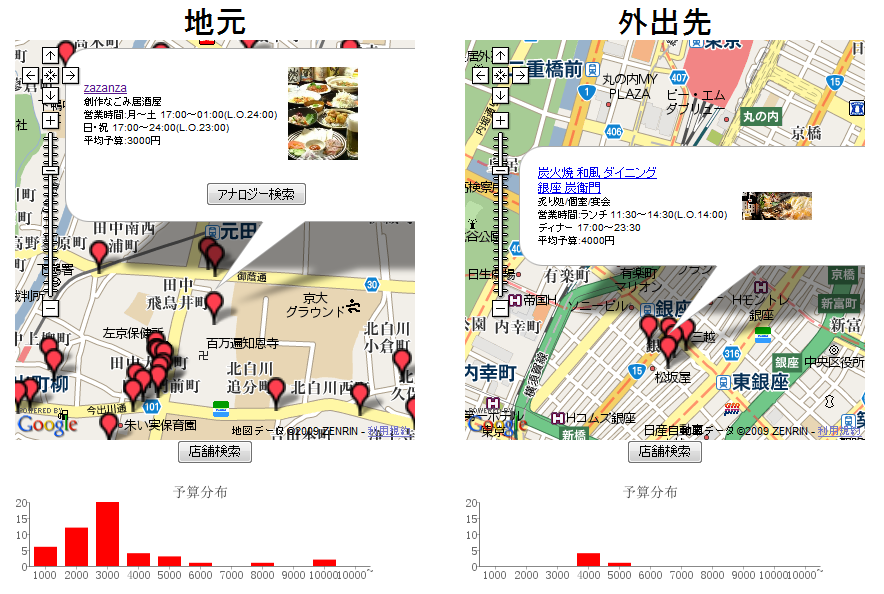
We propose a query-by-example geographic object search method for users that do not know well about the place they are in. Geographic objects, such as restaurants, are often retrieved using an attribute-based or keyword query. These queries, however, are difficult to use for users that have little knowledge on the place where they want to search. The proposed query-by-example method allows users to query by selecting examples in familiar places for retrieving objects in unfamiliar places. One of the challenges is to predict an effective distance metric, which varies for individuals. Another challenge is to calculate the distance between objects in heterogeneous domains considering the feature gap between them, for example, restaurants in Japan and China. Our proposed method is used to robustly estimate the distance metric by amplifying the difference between selected and non-selected examples. By using the distance metric, each object in a familiar domain is evenly assigned to one in an unfamiliar domain to eliminate the difference between those domains. We developed a restaurant search using data obtained from a Japanese restaurant Web guide to evaluate our method.
- Makoto P. Kato, Hiroaki Ohshima, Katsumi Tanaka: Content-based Retrieval for Heterogeneous Domains: Domain Adaptation by Relative Aggregation Points. In Proc. of the 35th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2012), pp. 811-820, 2012.
RhythMiXearch (2009)

- Makoto P. Kato: RhythMiXearch: Searching for Unknown Music by Mixing Known Music. In Proc. of 10th International Society for Music Information Retrieval Conference (ISMIR 2009), pp. 477-482, 2009.
Query by Analogical Example (2009)
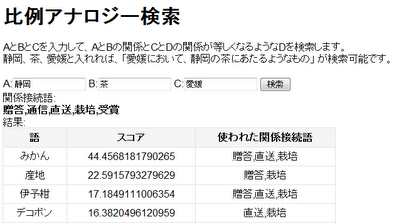
- Makoto P. Kato, Hiroaki Ohshima, Satoshi Oyama, Katsum Tanaka: Query by Analogical Example: Relational Search Using Web Search Engine Indices. In Proc. of the 18th ACM International Conference on Information and Knowledge Management (CIKM 2009), pp. 27-36, 2009.
Improving Web Image Search by Using Social Tags (2008)
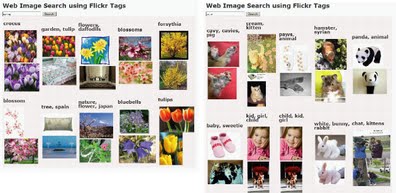
Conventional Web image search engines can return reasonably accurate results for queries containing concrete terms, but the results are less accurate for queries containing only abstract terms, such as “spring” or “peace.” To improve the recall ratio without drastically degrading the precision ratio, we developed a method that replaces an abstract query term given by a user with a set of concrete terms and that uses these terms in queries input into Web image search engines. Concrete terms are found for a given abstract term by making use of social tagging information extracted from a social photo sharing system, such as Flickr. This information is rich in user impressions about the objects in the images. The extraction and replacement are done by (1) collecting social tags that include the abstract term, (2) clustering the tags in accordance with the term co-occurrence of images, (3) selecting concrete terms from the clusters by using WordNet, and (4) identifying sets of concrete terms that are associated with the target abstract term by using a technique for association rule mining. Experimental results show that our method improves the recall ratio of Web image searches.
- Makoto P. Kato, Hiroaki Ohshima, Satoshi Oyama, Katsumi Tanaka: Can Social Tagging Improve Web Image Search? In Proc. of the 9th International Conference on Web Information Systems Engineering (WISE 2008), pp. 235-249, 2008.